Lane 01 · Foundations
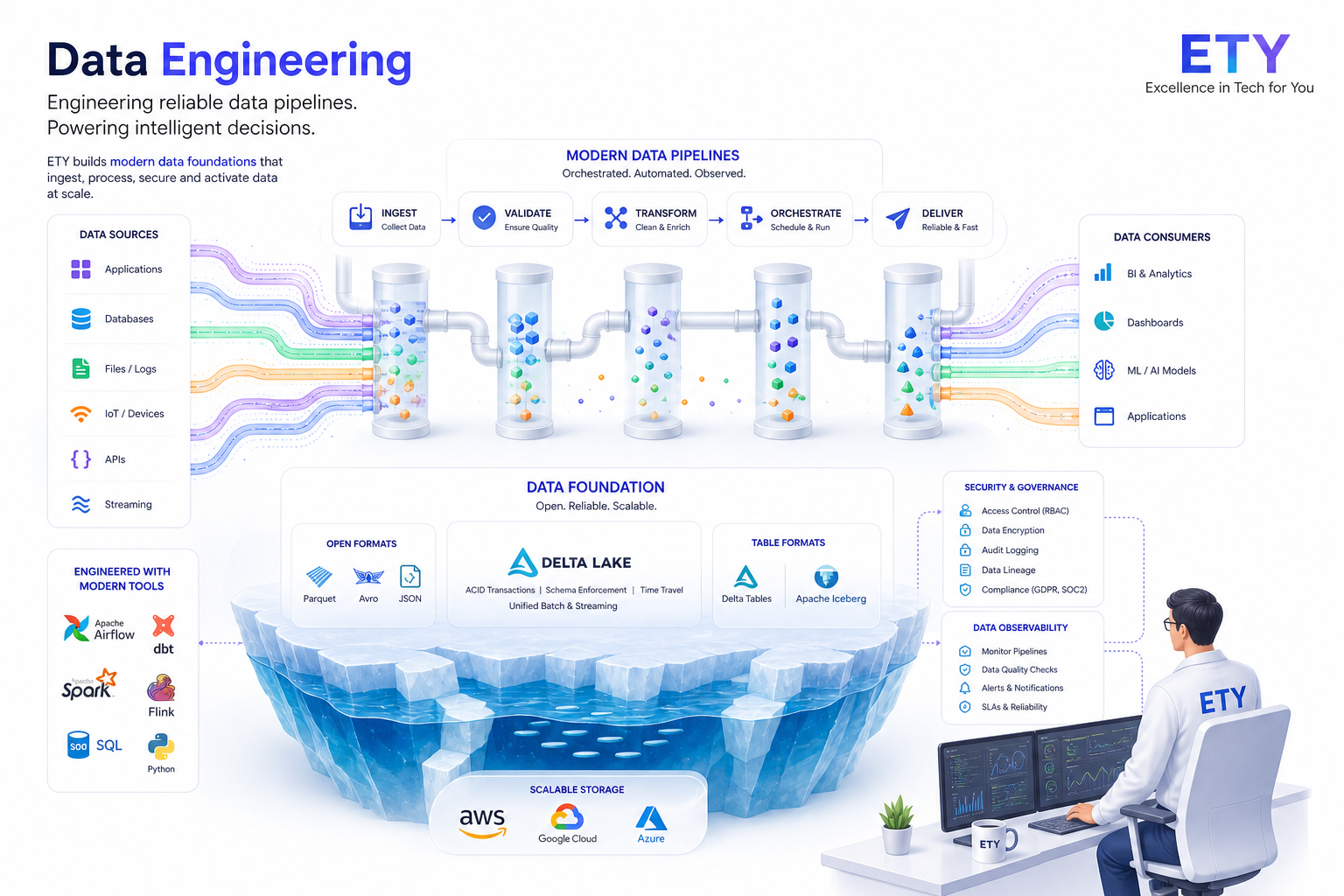
Ingest & Reliability
Source connectors, change-data-capture, schema evolution, and the boring observability that keeps you off the on-call pager.
- CDC & batch ingestion
- Schema registry & contracts
- Orchestration (Airflow / Dagster)
- Data quality & tests
- Lineage & observability